

代码仓库:https://gitee.com/qianminghuang/python-learning.git
提示
Python中万物皆是对象
ℹ️ Note
Python中万物皆是对象
可变类型与不可变类型
-
可变类型:在函数参数传递时,类似于引用。如字典、列表、集和。
-
不可变类型:在函数参数传递时,类似于值传递。如整数、字符串、元素。
可以使用.copy()来实现对于 可变对象 的复制,而不要使用=。=会使连个变量指向同一个可变类型对象的地址
1 | list1 = [1, 2, 3] |
输出:
1 | [1, 2, 3, 4] 地址为2227037551360 |
但是.copy()本质上还是浅拷贝,当对象中含有指针时,浅拷贝就会产生风险。这时就需要使用深拷贝.deepcopy()。.deepcopy()是依赖于copy()库的。
1 | import copy |
输出:
1 | original = [1, 2, 3, [4, 5, 6]] |
假设original指向了 [1,2,3,指针1] ,由于list_copy是浅拷贝而来的,所以其指向的是另一个内存单元的[1,2,3,指针1]。而因为list_deepcopy是深拷贝而来,所以其对列表内部的元素不仅仅是简单的复制值,但遇到指针时,其会开辟一个新的内存单元,然后指向新的内存单元。如下图所示。
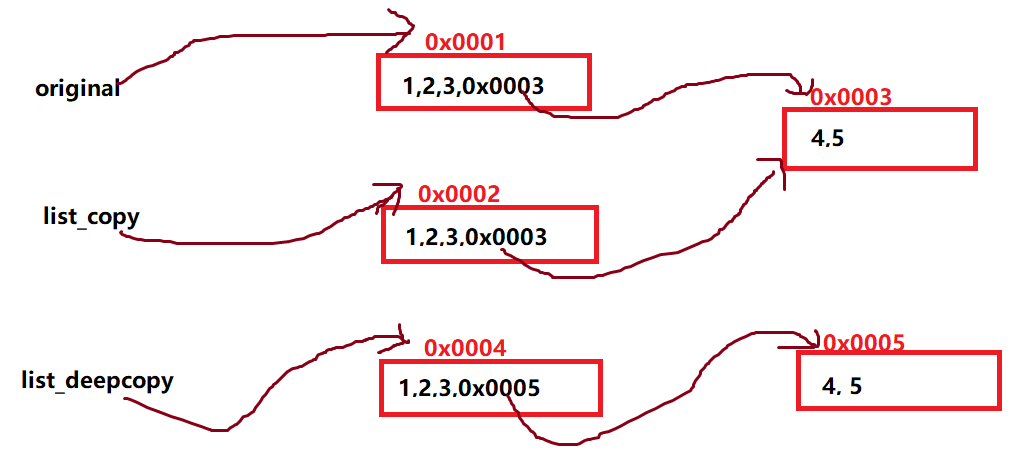
所以当original中指针1所示指向的空间中的内容被修改后,list_copy中指针1所指向的空间中的内容同样被修改,其二者指向的是同一个内存空间。
需要注意到是,这张图中只是展示概念。真正的数组保存不可能是一个内存单元存下了所有内容,而是开辟一段连续的内存空间保存这些值,original则指向了这段连续的内存空间的起始地址。
函数
::: tips
提示
当函数没有返回值的时候,函数默认返回None。
:::
None的应用
-
可以用于
if判断,None等价于False -
用于声明无初始内容的变量
1
name = None # 表示后续再给name赋值
变量的作用域
在函数内部,可以使用global关键词来设置全局变量。
1 | def test(): |
输出:

Lambda匿名函数
函数的定义有两种:
def关键字的方式,定义有名称的函数,可以重复使用。
lambda关键字,定义匿名函数,只能临时使用一次。
匿名函数的定义语法:
1 | lambda 传入参数: 函数体 |
注意,此处函数体只能一行。
具体案例:
1 | def test_func(compute): |
输出:

lambda函数具体应用场景:
-
临时构建一个函数,只用一次的场景
-
函数体只用一行
函数参数
不定长参数
位置传递的不定长参数
以*开头的参数,其会根据传进参数的位置合并出一个元祖。
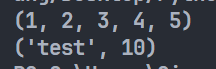
1 | def user_info_1(*args): |
输出:
关键字传递的不定长参数
以**开头,参数是键值对的形式,返回的是一个字典。
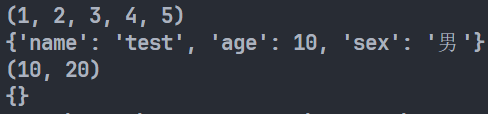
1 | def user_info_2(**kwargs): |
输出:

结合使用:
1 | def user_info_3(*args, **kwargs): |
输出:
函数作为参数
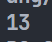
1 | def test_func(compute_func, a, b): |
输出:
本质上传递的是代码的执行逻辑
数据类型
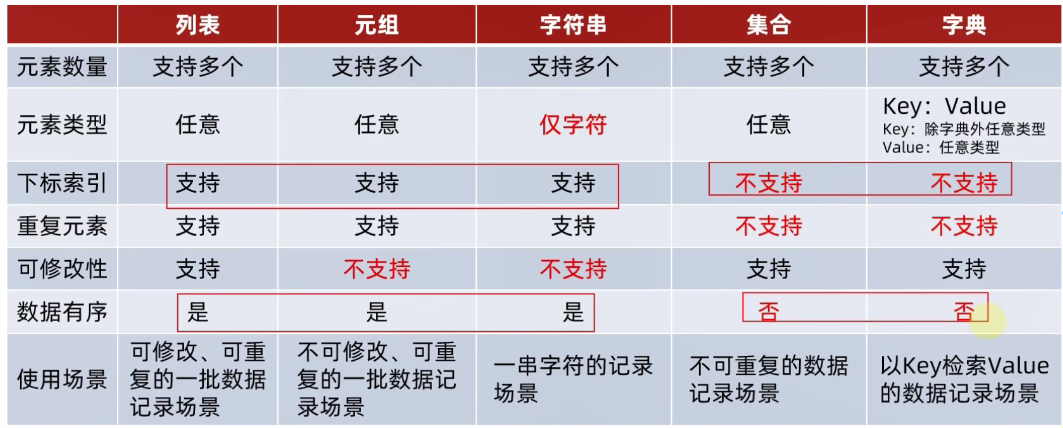
-
列表:
[],一批数据,可修改 -
元组:
(),一批数据,不可修改 -
集和:
set(){},用于去重操作
异常
了解异常
异常:程序运行的时候检测到一个错误,这个错误将导致Python解释器无法继续执行。
也可以理解为一个Bug。
异常的捕获方式
-
异常捕获的目的
对可能出现的异常(bug),提前做准备。具体而言就是对Bug进行提醒,并且让整个程序继续运行。这样就可以避免因为一个Bug而导致的整个程序的停止。
捕获常规异常
基本语法:
1 | try: |
案例:
1 | try: |
当try语句中出现异常后,程序不会抛出异常,而是使用except来让程序继续运行
捕获指定的异常
基本语法:
1 | try: |
案例:
1 | try: |
结果:

捕获多个异常
基本语法:
1 | try: |
捕获所有异常
最简单的try except语句就可以捕获所有异常了,但是没法对所捕获到的异常进行输出。
基本语法:
1 | try: |
通过输出异常的别名就可以看到捕获的异常是什么。
else 与 finally
else用于表示在没有异常的时候该执行什么行为。
基本语法:
1 | try: |
::: tips
提示
finally中一般都是用来执行资源关闭操作,比如文件的关闭
:::
案例:
1 | try: |
输出:
异常的传递
假设有函数调用关系如下
1 | main() |
当func02()的代码中出现异常后,异常会向上逐级传递(从func02() -> func01() -> main() ),这条传递线上的任意一个函数有对异常的捕获都将使程序可以继续执行。
抛出异常
使用raise可以抛出一个我们想要的异常。
基础语法:
1 | raise 异常 |
抛出的异常一定要是异常的实例或者使异常的类,即Exception的子类。例如可以是NameError('that is a name error')。因为NameError是Exception的一个子类,所以这里创建了一个异常的匿名对象。
举例:
1 | x = 4 |
输出:
1 | File "c:/Users/QianmingHuang/Desktop/Python-Learning/异常.py", line 32, in raise_func |
自定义的异常
用户需要创建一个继承了Exception类的类。
::: tips
提示
有时候需要给一个模块写若干个自定义的异常
:::
举例:
1 | class ExamError(Exception): |
输出结果:
1 | Submission failed: You cannot submit the exam after the deadline. |
在上面这个案例中就展示了自定义异常的一个场景。对于提交的异常可以专门写一个类SubmissionError,对于别的异常,比如答题中的异常,也可以专门写一个类来应对。
面向对象
类
1 | 变量名 = 类名() # 类的实例化 |
类名()创建出了一个匿名对象,变量名也是一个对象,其指向了这个匿名对象。更确切的说,变量名是通过类名()创建出的匿名对象的引用。
对于每一个对象来说,其都拥有自己的内存空间,保存着自己的属性。但是来自同一个类的不同对象共享类的方法,也就是说类的方法在内存中只有一份,在使用类的方法时,要把对象的引用(可以理解为当前调用此方法的实例的地址,类比C++中的this指针)传递到方法内部。
在python中有两种类。分别是新式类和旧式类,主要区别是新式类继承自object类,而旧式类不是。自python3开始,一切的类都是新式类
-
__del__方法如果说
__init__方法类比于 C++ 的构造函数,那么__del__方法就可以类比于 C++ 的析构函数。 -
__str__方法此方法的作用是咱输出对象变量的时候,可以输出自定义的内容。
1
2
3
4
5
6class 类名1:
def __str__(self):
return 想输出的字符串
对象变量名1 = 类名1()
print(对象变量名1)注意
__str__方法的返回值必须是 字符串
私有属性和私有方法
-
定义方法:
在属性或者方法前面加上两个下划线
1
2
3
4
5
6
7class Women:
def __init__(self, name):
self.name = name
self.__age = 18 # 私有属性,外部不可访问
def __secret(self): # 私有方法,外部可不访问
print("%s 的年龄是 %d" % (self.name, self.__age)) -
python中没有真正意义上的私有
-
在给属性、方法命名是,实际上是对名称作了一些特殊处理,使外界无法访问到
-
通过
_类名__私有方法\属性可以访问私有方法和属性1
2xiaohong = Women("xiaohong")
xiaohong._Women__secret() # 此时就可以访问私有方法啦
-
类也是对象
开篇第一句话是:python中万物皆为对象。类也不意外,可以把其看做类对象。
类对象在内存中只有一个,一个类对象可以创建多个实例。
正因为类是一个对象,所以其拥有自己的 类属性 和 类方法。二者都可以通过类名·的方式来访问
-
类属性
仅仅用于记录类的特征,无法用于记录实例特征。
1
2
3
4
5
6class Counter:
# 类属性:用于统计实例数量
instance_count = 0
def __init__(self):
Counter.instance_count += 1 # 通过 类名.类属性 的方式调用也可以使用
实例.类属性的方式调用类属性(向上查找机制),但是十分不推荐。比如实例.类属性 = 1的时候,实际上是给实例增加了一个属性,而不是对类属性的值进行了修改。 -
类方法
类方法需要用到修饰器
@classmethod,其只能访问 类属性 和 类方法。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15class ParentClass:
class_variable = "这是父类的类变量"
# 必须要有@classmethod修饰
def class_method(cls): # 类方法的第一个参数必须是cls
return f"调用了 {cls.__name__} 的类方法,类变量值为: {cls.class_variable}"
class ChildClass(ParentClass):
class_variable = "这是子类的类变量"
# 子类调用父类的类方法
result = ChildClass.class_method()
print(result)输出:
1
调用了 ChildClass 的类方法,类变量值为: 这是子类的类变量
因为
cls的存在,类方法知道其是被哪个类对象调用的。当ChildClass类调用了类方法class_method()后,cls收到了ChildClass类的引用(可以理解为cls此时成为了ChildClass),也就调用了ChildClass的类属性。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16class Student:
def __init__(self, name, age):
self.name = name
self.age = age
def from_string(cls, info):
name, age = info.split(' ')
return cls(name, age) # 此处等价于Student(name, age),因为cls指向Student类
s1 = Student("小明", 10)
s2 = Student("小李", 20)
s3 = Student.from_string("小红 14") # 调用类方法处理特殊输入
for s in [s1, s2, s3]:
print(f"s.name = {s.name}, s.age = {s.age}")输出:
1
2
3s.name = 小明, s.age = 10
s.name = 小李, s.age = 20
s.name = 小红, s.age = 14
静态方法
静态方法需要用到修饰器@staticmethod。其既不需要cls也不需要self作为输入,好似独立于类而存在。但是其依旧可以用类名.的方式来访问。
1 | class MathUtils: |
输出:
1 | 3 和 5 相加的结果是: 8 |
可以发现,静态方法并不保存在类对象中。
嵌套类
类中是可以再定义类的。
1 | class A: |
这等价于下面的写法:
1 | class B: |
这就是说类B的实例b是类A的类方法
继承
除了继承父类的属性和方法外,还可以对父类的方法进行重写。重写可以分为两种方式。
-
覆盖:在子类中定义了一个和父类同名的方法并且实现。
-
扩展:在子类中定义了一个和父类同名的方法,在其中使用了父类同名的方法。这时就需要
super类出场了。通过
super()的方式生成一个匿名对象,其会按照__mro__属性的顺序来访问父类。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22class A:
def method(self):
print("A 的方法")
class B(A):
def method(self):
print("B 的方法")
super().method()
class C(A):
def method(self):
print("C 的方法")
super().method()
class D(B, C):
def method(self):
print("D 的方法")
super().method()
d = D()
d.method()
print(D.__mro__)输出:
1
2
3
4
5D 的方法
B 的方法
C 的方法
A 的方法
(<class '__main__.D'>, <class '__main__.B'>, <class '__main__.C'>, <class '__main__.A'>, <class 'object'>)可以看出,父类方法调用的顺序就是
__mro__中设置的顺序。因此,__mro__将会帮助用户来解决来自不同父类的同名函数的调用问题。::: danger
警告
但是,最好不要通俗的认为super()就是一个父类对象。可以具体看后面的这两组实验。
:::1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17class ParentClass:
def class_method(cls):
print(f"调用了 {cls.__name__} 的类方法")
print(id(cls))
class ChildClass(ParentClass):
def class_method(cls):
print(f"调用了 {cls.__name__} 的类方法,现在要调用父类的类方法")
print(id(cls))
super().class_method()
# 调用子类的类方法
ChildClass.class_method()输出:
1
2
3
4调用了 ChildClass 的类方法,现在要调用父类的类方法
2153593471488
调用了 ChildClass 的类方法
2153593471488现在,只将
super()改成ParentClass,即父类类名。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17class ParentClass:
def class_method(cls):
print(f"调用了 {cls.__name__} 的类方法")
print(id(cls))
class ChildClass(ParentClass):
def class_method(cls):
print(f"调用了 {cls.__name__} 的类方法,现在要调用父类的类方法")
print(id(cls))
ParentClass.class_method() # 此处做出了修改!
# 调用子类的类方法
ChildClass.class_method()输出:
1
2
3
4调用了 ChildClass 的类方法,现在要调用父类的类方法
2153593459216
调用了 ParentClass 的类方法
2153593465824可以看出,此时的
cls的地址是不一样的。而使用super()的时候,cls的地址则是相同的。
多态
在C++中,多态的实现是通过父类指针或引用指向子类对象实现的。而python中也是如此,只不过因为python中没有指针的显式概念,所以可以进一步理解为:不同的子类对象调用同名的父类方法,产生不同的执行结果。
1 | # 定义一个基类 |
输出:
1 | 汪汪汪! |
多线程
每个线程都有属于其自己的一组CPU寄存器(比如指令指针和堆栈指针寄存器),这组CPU寄存器被称为“线程的上下文”。线程的上下文可以被想象为一个线程的“个人信息包”,它包含了线程运行时需要的各种状态信息。
当线程被调度执行时,CPU 会根据该线程的上下文信息来设置 CPU 寄存器的状态,使其恢复到上次该线程运行时的状态。这样,线程就可以从上次停止的地方继续执行下去。比如,线程在执行一个复杂的数学计算,由于某种原因(如时间片用完)暂停了执行,当时 CPU 寄存器中保存了计算的中间结果和指令指针等信息。当该线程再次被调度执行时,通过其上下文恢复 CPU 寄存器的状态,就能够继续进行之前未完成的计算,而不会丢失之前的工作进度。
注意
多线程是宏观上的并行,微观上的并发。
线程是可以被中断的。当别的线程正在运行时,线程可以暂时进入睡眠状态,即线程的退让。
同一个进程下的多个线程是共享内存空间的。
-
线程可以被分为两种:
- 内核线程:操作系统内核进行管理
- 用户线程:用户在程序中管理
threading模块
threading模块中的Thread类就是用于初始化线程的。可以通过其直接生成一个线程示例。
1 | import threading |
输出:
1 | 0 |
-
Thread类的__init__函数有用的参数:-
target:线程要执行的目标函数
-
name:线程名字
-
args:目标函数的参数,按位置传递
-
kwargs:目标函数的参数,按关键字传递
1
2
3
4
5
6
7
8
9
10
11import threading
def print_info(a = 10, b = 20, c = 30, d = 40, e = 50):
print(f"a: {a}, b: {b}, c: {c}, d: {d}, e: {e}")
# 创建线程并同时传递位置参数和关键字参数
thread = threading.Thread(target=print_info, args=(1,), kwargs={"c" : 5, "e": 4})
# 启动线程
thread.start()
# 等待线程结束
thread.join()输出:
1
a: 1, b: 20, c: 5, d: 40, e: 4
-
daemon:线程是否为守护线程。
::: tips
提示
守护线程是一种特殊的线程,其会在主线程退出时自动终止。这就意味着,当程序中只剩下守护线程的时候,主线程会直接结束。与之相对的是非守护线程,主线程会等待所有非守护线程执行完毕后才会退出程序。
:::1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24import threading
import time
def daemon_function():
print("Daemon thread started")
time.sleep(5)
print("Daemon thread finished")
def non_daemon_function():
print("Non-daemon thread started")
time.sleep(2)
print("Non-daemon thread finished")
# 创建守护线程
daemon_thread = threading.Thread(target=daemon_function, daemon=True)
# 创建非守护线程
non_daemon_thread = threading.Thread(target=non_daemon_function)
# 启动线程
daemon_thread.start()
non_daemon_thread.start()
print("\nMain thread continues...")
# 主线程不做额外等待,直接结束输出:
1
2
3
4
5Daemon thread started
Non-daemon thread started
Main thread continues...
Non-daemon thread finished::: danger
警告
在jupyter notebook中的结果可能不同。其可能会输出到 Daemon thread finished。
:::-
使用场景:
- 后台任务:当用户需要在程序运行过程中执行一些后台任务,且这些任务不需要保证一定执行完毕时,可以使用守护线程。例如,日志记录、监控系统状态等任务。
- 避免资源泄露:如果线程执行的任务在主线程退出时没有必要继续执行,将其设置为守护线程可以避免资源泄漏。比如,一些临时文件的清理工作,如果主线程已经退出,这些清理工作也就没有必要继续执行了。
-
-
Thread类中的其他方法、属性
-
start(self):启动线程,将调用线程的。 -
run方法。run(self):线程在此方法中定义需要执行的代码。 -
join(self, timeout=None):等待线程终止。此方法会一直阻塞,直到被调用的线程终止。 -
timeout参数定义了最多等多少秒。 -
is_alive(self):判断线程是否还在运行。 -
getName(self):获取线程名字。 -
setName(self):设置名字。 -
ident:线程的唯一标识符。 -
isDaemon(self):返回是否为守护线程。
除了直接使用Thread类来初始化一个线程实例,设置一个继承其的子类,并重写其run方法也可以实现多线程。
1 |